Anoteros was tasked by the client to enhance their commercial offerings by automating regulatory data collection and address discovery for listings. Our approach followed a structured, multi-phase methodology: Assess, Prototype, Review, and Implement.
Our engagement began with the Assess phase. During this initial stage, we conducted a current state assessment, looking at existing data sources, experimenting with image comparison, identifying AI/ML opportunities, evaluating new data sources, and developing a milestone plan. This involved reviewing data sources with the client’s internal SMEs and identifying markets for a Proof of Concept (POC).
Following the assessment, we moved into the Prototype phase. In this phase, Anoteros built and validated prototypes through automated solutions, leveraging learnings from the Assess phase. This involved utilizing AI/ML models and developing automated validation methods to ensure the efficacy of our solutions. Both the regulatory data and the address discovery POCs were actively prototyped during this period, incorporating AI/ML and developing validation methods.
The project then progressed to the Review phase. Here, we aggregated findings from the Prototype phase, developed recommendations for the path forward, and reviewed these findings and recommendations with the client’s leadership team. A summary of findings from the Prototype phase and an implementation plan with a proposed budget were also developed.
Requirement 1: Automating Regulatory Data Discovery & Insights for Short-Term Rentals
Business Challenge & Requirements:
The organization sought to gather city-specific short-term rental regulations and automatically generate clear summaries of complex information such as permitting requirements, zoning rules, and other local restrictions.
The inherent challenges with this requirement included:
- Data Fragmentation and Volatility: Regulatory information is not centralized. It is scattered across disparate sources such as municipal websites, city planning documents, public announcements and discussion forums. The frequent updates to these regulations mean any manually collected data quickly becomes obsolete.
- Semantic Complexity: Municipal regulations are written in dense, legal language. An automated solution must be able to parse this language to accurately identify and extract specific data points such as duration limits, occupancy rules, permit fees, and zoning restrictions.
- Scalability: Manually scaling the research process to over 100 cities is operationally and financially unfeasible. Each new city adds a significant burden on the analyst team, making a manual approach impossible to maintain at scale.
- Trust and Reliability: A core challenge for any automated solution is establishing trust. The system must not only retrieve information but also have confidence in the authority of its sources. A significant technical hurdle is mitigating the risk of LLM “hallucinations”—where the AI generates plausible but incorrect information—to ensure data trust
Our Solution & Technical Implementation:
To overcome these challenges, Anoteros engineered a sophisticated AI agent designed for automated data discovery and insight generation. This system was built to dynamically crawl the web and extract up-to-date regulatory information from trusted sources
Our implementation involved several key techniques:
- An AI agent leveraging a combination of Large Language Models (LLMs), including Gemini, Claude, and models from OpenAI and Perplexity, was developed to ensure high accuracy and appropriate tone.
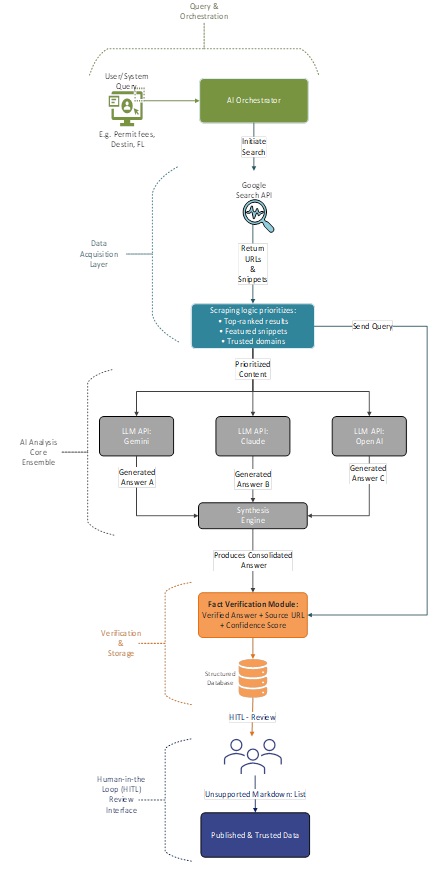
- Intelligent Source Prioritization: The system leverages Google Search for real-time web discovery. To ensure source reliability, our scraping logic was designed to prioritize content from top-ranked search results and give special weight to information in Google’s featured answers, using search engine ranking as a strong proxy for source authority. This aligns with our goal of parsing only trusted content.
- Retrieval-Augmented Generation (RAG): To ensure contextual grounding and mitigate model confabulation, we implemented a Retrieval-Augmented Generation (RAG) framework. This system dynamically retrieves the most pertinent and up to date text segments from our prioritized sources based on specific evaluation criteria (e.g., ‘maximum occupancy,’ ‘permit fees’). This retrieved content is stored/indexed and provided as a rich, factual context to the LLM, compelling it to generate answers that are strictly grounded in the verified source material.
- Ensemble Learning for Accuracy: Rather than relying on a single model, we employed an ensemble learning technique. The system queries multiple leading LLMs simultaneously—including Gemini, Claude, OpenAI, and Perplexity models —and then intelligently synthesizes their outputs. This approach creates a more robust and accurate result than any single model could produce alone, effectively cross-verifying the information and minimizing the risk of model-specific errors or hallucinations.
- Robust Fact-Verification: After the ensemble model generates an answer, we deployed dedicated fact-verification layers. This final step cross-references the synthesized information against the prioritized source documents to avoid hallucinations and ensure the highest degree of data trust.
- Traceability for Human Review: To facilitate a final layer of human oversight, the system’s output explicitly includes the source URLs as citations alongside the AI-generated answers. This critical feature enables a human-in-the-loop review process, allowing the client’s analysts to quickly and easily validate the data’s origin before publication, cementing confidence in the final product.
- Advanced Data Processing: We used semantic clustering to group similar information, avoid data duplication, and ensure comprehensive coverage of all relevant regulations. The system was also designed with flexible output formatting for seamless integration into the client’s downstream products.
Diagram 1: Regulatory Data Hybrid Approach Workflow – A flowchart illustrating the process from Google Search result ranking and scraping, feeding content to an LLM, generating tailored answers, populating a database with source links and content, and finally, manual review (Click to enlarge)
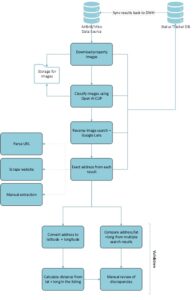
Requirement 2: Automating Address Discovery
Business Challenge & Requirements:
The client sought a method to discover the exact street addresses of property listings found on leading short-term rental websites. This address data is a critical missing link needed to derive valuable data correlations—such as comparing a listing’s performance to local real estate values or neighborhood trends—and ultimately improve their product offerings.
The challenges associated with this requirement are significant:
- Deliberate Data Obfuscation: STR platforms intentionally conceal exact property addresses for the privacy and security of hosts. They typically only show a general radius on a map, making direct extraction impossible.
- Lack of a Single Source: There is no straightforward way to find an address. The solution requires a creative, multi-modal approach that can piece together clues from different data types (images, text) and external sources.
- Scalability: The solution needed to be viable for millions of properties across hundreds of cities, demanding a highly efficient and cost-effective architecture to handle massive volumes of data processing.
Our Solution & Technical Implementation:
We engineered a creative and highly effective automated address discovery solution. Our initial research explored several potential methods, including attempting to match property photos with Google Maps Street View imagery. However, we ultimately developed a more robust and scalable multi-step process that yielded superior results.
The core components of our final solution include:
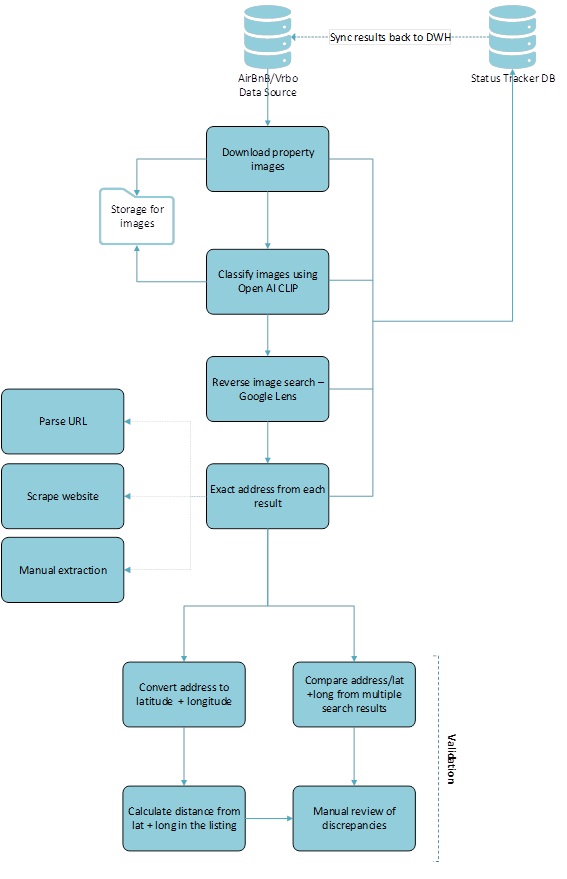
- Image Acquisition & Classification: For a given listing, we first downloaded all available images. We then used OpenAI CLIP for image classification to analyze the photos and identify specific, high-value images, such as exterior shots showing the front elevation of the property.
- Targeted Reverse Image Search: The classified front elevation images were then used to perform a reverse image search using Google Lens. To avoid false positives, we configured the system to only consider exact image matches from the search results.
- Source Prioritization & Extraction: We prioritized results from reputable real estate websites (e.g., Zillow, Compass) and other sources from which an address could be reliably extracted. The system then scraped the precise street address from these high-priority pages.
- Geocoding & Validation: The extracted addresses were converted into precise latitude and longitude coordinates using geocoding for address conversion. We then calculated the distance between our discovered coordinates and the approximate location provided on STR websites’ listings to assess accuracy.
- Refined Validation Logic: To ensure the highest quality, we developed a rules-based validation system. This included automatically selecting the closest address match or flagging a listing for manual review if the calculated distance exceeded a set threshold or if search results pointed to multiple different street addresses.
This entire solution was designed to be highly scalable, capable of processing millions of properties across hundreds of cities.
Diagram 2: Address Matching Workflow – A flowchart depicting the flow from property image download, classification by Clip by OpenAI, reverse image search via Google Lens, extraction of addresses from search results, conversion to lat/long, distance calculation, and validation (Click to enlarge)